This post presents "Single channel voice separation for unknown number of speakers under reverberant and noisy settings", a deep separation model that is trained on noisy reverberant data.
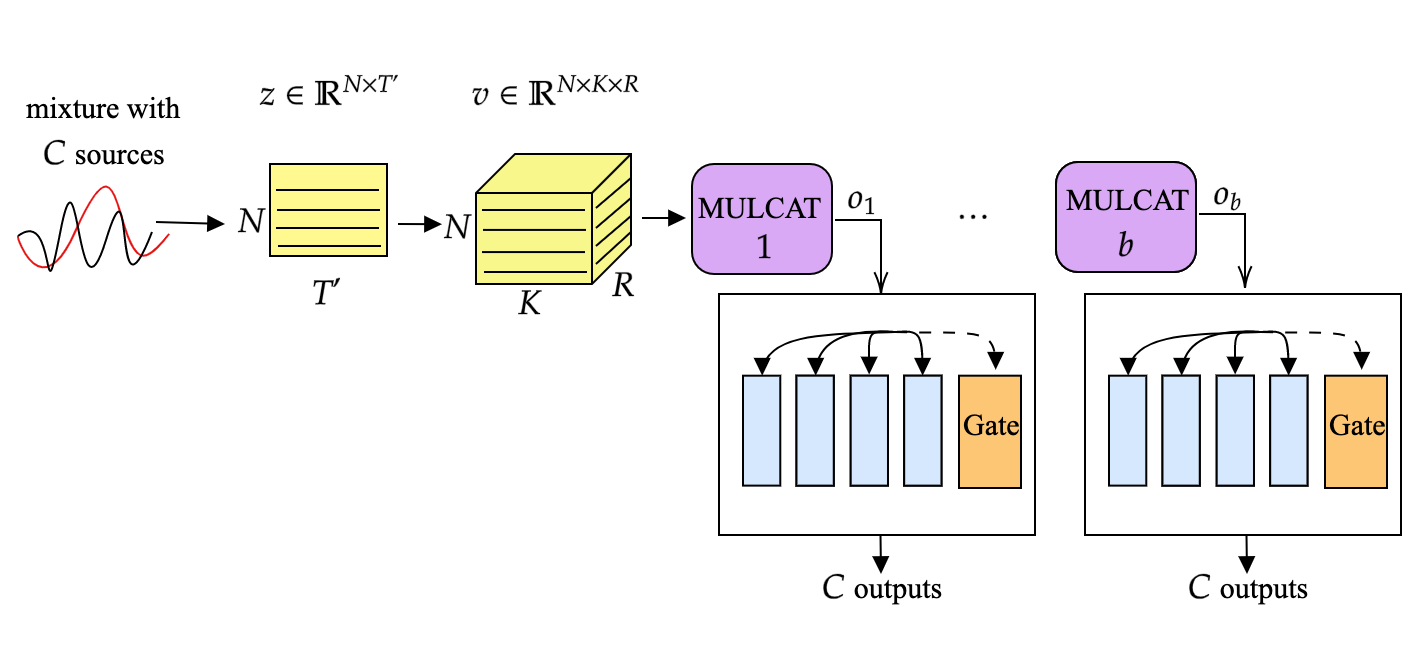
We present a unified network for voice separation of anunknown number of speakers.
The proposed approach is composed of several separation heads optimized together with a speaker classification branch.
The separation is carried out in the time domain, together with parameter sharing between all separation heads.
The classification branch estimates the number of speakers while each head is specialized in separating a different number of speakers.
We evaluate the proposed model under both clean and noisy reverberant settings. Results suggest that the proposed approach is superior to the baseline model by a significant margin.
Additionally, we present a new noisy and reverberant dataset of up to five different speakers speaking simultaneously.
Network Architecture
Real life example
This example was recorded using a laptop microphone in higly reverberant room. The male speaker was 2.5m away from the microphone while the female speaker was 1m away.
Mixture:
Spk #1:
Spk #2:
Here are some samples from our model for you to listen:
- Mixture input - original mixed audio
- Ours - our proposed method
Clean dataset
WSJ-2mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-3mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-4mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-5mix DB Samples
| Mixture input | Ours |
|---|---|
Noisy dataset
WSJ-2mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-3mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-4mix DB Samples
| Mixture input | Ours |
|---|---|
WSJ-5mix DB Samples
| Mixture input | Ours |
|---|---|